The advent of ChatGPT is just the tip of the iceberg of the emerging natural language processing (NLP) technologies and applications that are fundamentally changing human-computer interaction and, ultimately, our daily work.
With the increased adoption of model architectures and frameworks, developers are focusing more and more on improving the data used to train AI systems. Taking a data-centric approach enables them to use a set of common algorithms and then increase the number of training samples severalfold (e.g., from 10,000 to 50,000) or reduce the number of errors in the training data.
This is why we are excited to back Kern AI, a data-centric platform to power natural language products, workflows, and ETL pipelines. Founded by Johannes Hötter and Henrik Wenck in November 2020, the Germany-based company is building a platform designed for developers who want to implement data-centric NLP solutions. Its use cases range from internal workflows for operational or analytical purposes, such as complex customer-facing services, to building sophisticated NLP applications with their platform as the training database.
Johannes Hötter highlights:
“Kern AI aims to build software with an outstanding developer experience. We strive to provide users with the flexibility to create what they want and to reduce the time between an idea and its implementation. We are confident that Natural Language Processing (NLP) will continue to grow, and with Kern AI’s modular platform, developers have all the resources they need to deploy use cases. This is what we excel at and what we want to demonstrate to the world.”

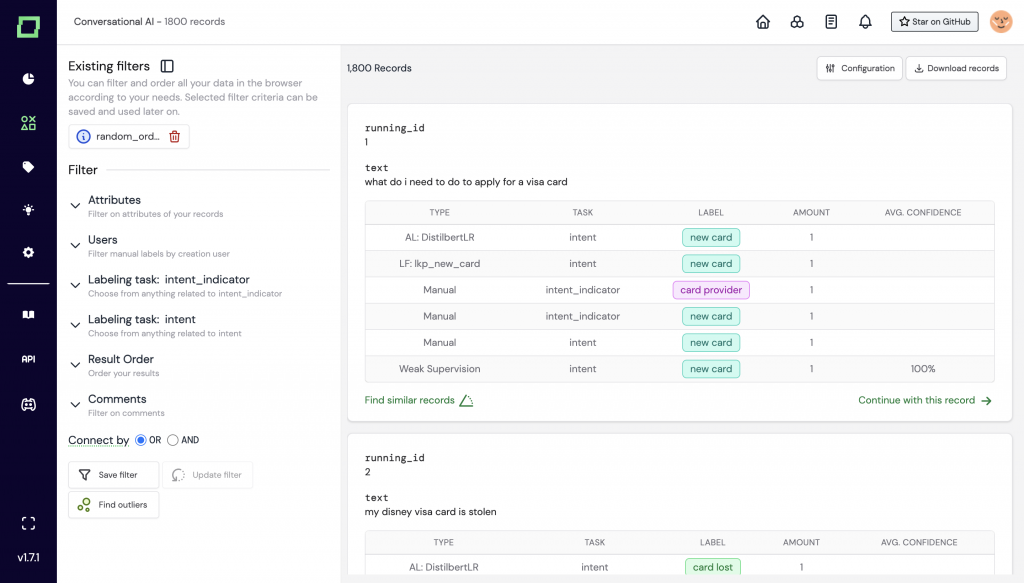
Since launching in July 2022, the open-source version of refinery and of the content-library bricks have reached several thousand developers. Both projects are available to download on Kern AI’s GitHub page.
Aiming to empower developers to manage complexity, the Kern AI ecosystem consists of four products:
- refinery – combines training data and algorithms in a way that developers and data scientists can easily build NLP automations
- bricks – a collection of modular and standardized code snippets which can be directly integrated into refinery
- gates – an online monitoring and inference API for data-centric models
- workflow – the orchestration layer for natural language-driven tasks that allows building complex workflows, which can be triggered by a variety of events
The company’s suite of products is used by data scientists at AI-driven organizations (including Samsung, Barmenia, DocuSign, co:here, and Seedcamp-back crowddev) to perform label automation, cleansing, and monitoring. Further possible applications include retrieval, outbound classification, named entity recognition, sentimental analysis, and more.
On why we invested, our Managing Partner Carlos Espinal comments:
“Johannes and Henrik have a deep understanding of the needs of NLP developers and data scientists and the ability to execute efficiently at scale. With their unique product insights and developer-centric approach, Kern AI is well positioned to become a fundamental tool for every company leveraging NLP.”
We are excited to co-lead Kern AI’s €2.7 million seed round alongside Faber, with participation from xdeck, another.vc, TKM Family Office, and business angels Marcus Nagel, Julius and Sebastian Heinz, Nicolas Peters, and Gerrit de Veer.
With the fresh funding, the team plans to expand their platform’s capabilities and use case catalogue, grow their developer community, and make it generally available to the public.
Starting today, Kern AI also onboards individual developers in their free tier. Join the waitlist and request a demo at kern.ai.